
{kind=link}
Data Extraction from PDF, scanned documents with LLM and AI OCR – Powered by elDoc
In today’s enterprise environments, critical business data is often locked inside PDFs—contracts, invoices, reports, forms, and scanned documents. Extracting this data manually is slow, error-prone, and nearly impossible to scale across growing volumes and increasingly complex document formats.
This is where elDoc transforms the game.
By combining advanced AI OCR (Optical Character Recognition) with LLMs (Large Language Models), elDoc enables intelligent, automated, and highly accurate data extraction from any type of PDF—whether structured, semi-structured, or completely unstructured. Crucially, no templates, predefined models, or manual configuration are required any longer. The platform dynamically understands document layouts, interprets context, and identifies relevant data fields on the fly.
This means organizations can process diverse document types without the need for constant reconfiguration or rule maintenance unlocking true scalability, faster deployment, and significantly reduced operational overhead.
The Challenge of Traditional OCR Processing Systems
While traditional OCR solutions were a major step toward digitizing documents, they fall short of meeting modern enterprise needs especially when dealing with complex, high-volume, and variable document types.
Most organizations encounter the following limitations:
✔ Traditional OCR focuses on character recognition, not understanding
✔ Extracted text is often unstructured and disconnected from context
✔ Accuracy drops significantly with poor-quality scans, handwritten content, or complex layouts
✔ Heavy reliance on templates and predefined rules for each document type
✔ Frequent manual configuration and ongoing maintenance are required
✔ Inability to adapt to new or changing document formats without rework
✔ Limited or no capability for validation, reasoning, or cross-document checks
As a result, traditional OCR systems create additional layers of complexity rather than eliminating them. Organizations must invest time in building templates, maintaining rules, and validating outputs—turning what should be an automated process into a semi-manual workflow.
At scale, this becomes unsustainable. Instead of enabling automation, traditional OCR often leads to fragmented processes, inconsistent data quality, and operational inefficiencies, preventing businesses from achieving true end-to-end document intelligence.
The elDoc Approach: AI OCR + LLM = True Document Intelligence
elDoc combines two powerful technologies into one seamless pipeline:
1. AI OCR — Turning Any PDF into Machine-Readable Content
elDoc provides flexibility in how OCR is applied by allowing clients to choose which OCR engine best fits their requirements. It supports multiple leading technologies including PaddleOCR, Google Vision AI, and Tesseract and enhances them with advanced Visual Language Models (VLMs) for deeper document understanding.
This approach gives organizations full control to align OCR selection with their priorities whether that’s cost efficiency, on-premise deployment, language support, or accuracy for specific document types.
Using advanced AI-based OCR (augmented with visual models), elDoc can:
✔ Extract text from scanned PDFs, images, and handwritten elements
✔ Preserve document structure (tables, sections, key-value pairs, spatial layout)
✔ Handle multi-language and mixed-language documents
✔ Process low-quality scans, complex formats, and noisy inputs
✔ Work across highly variable document types without templates
Unlike traditional OCR, which focuses only on text extraction, elDoc’s AI OCR combined with visual understanding captures layout, positioning, and semantic grouping, enabling far more accurate downstream processing.
2. LLM-Powered Data Extraction — From Text to Meaning
Once the text and layout are extracted, LLMs convert this information into structured, meaningful data.
Rather than relying on rigid templates or predefined rules, elDoc uses LLMs to dynamically interpret each document in context—regardless of format or variability.
LLMs enable elDoc to:
✔ Identify and extract key data fields (e.g., invoice number, dates, totals, entities)
✔ Understand context and relationships across the document
✔ Normalize outputs into structured formats such as: JSON, CSV
✔ Handle unstructured and inconsistent layouts without reconfiguration
✔ Apply business rules, validations, and cross-field logic
✔ Adapt to new document types with no manual setup
This is the fundamental shift:
👉 elDoc doesn’t just read documents—it understands, structures, and validates them, turning raw content into reliable, ready-to-use data for enterprise systems and decision-making.
End-to-End Data Extraction Workflow in elDoc
A typical elDoc extraction pipeline is designed to move seamlessly from raw documents to validated, structured data—ready for enterprise use. Each step is automated, yet flexible enough to support business-specific controls and requirements.
1. Document Ingestion
Documents can enter elDoc from multiple channels, ensuring flexibility across business operations:
✔ API integrations with upstream systems
✔ Email inboxes (e.g., invoices, contracts received externally)
✔ File uploads via user interface or portals
✔ Scanners and batch processing systems
✔ Shared folders or enterprise storage systems
This allows organizations to centralize document intake regardless of source or format.
2. AI OCR Processing
Once ingested, documents are processed using AI OCR:
✔ Text is extracted from native PDFs, scanned documents, and images
✔ Layout elements such as tables, headers, and key-value structures are preserved
✔ Visual context (positioning, grouping) is captured for downstream understanding
✔ Selected OCR engine (e.g., PaddleOCR, Google Vision AI, or Tesseract) is applied based on client preference
At this stage, documents are transformed into machine-readable and structurally rich representations.
3. LLM-Based Interpretation
LLMs analyze the extracted content to understand meaning and context:
✔ Identify key data points (e.g., invoice number, dates, totals, entities)
✔ Interpret relationships between fields (e.g., totals vs. line items)
✔ Handle variability across document formats without templates
✔ Understand semantics, not just text
This step converts raw extracted content into context-aware information.
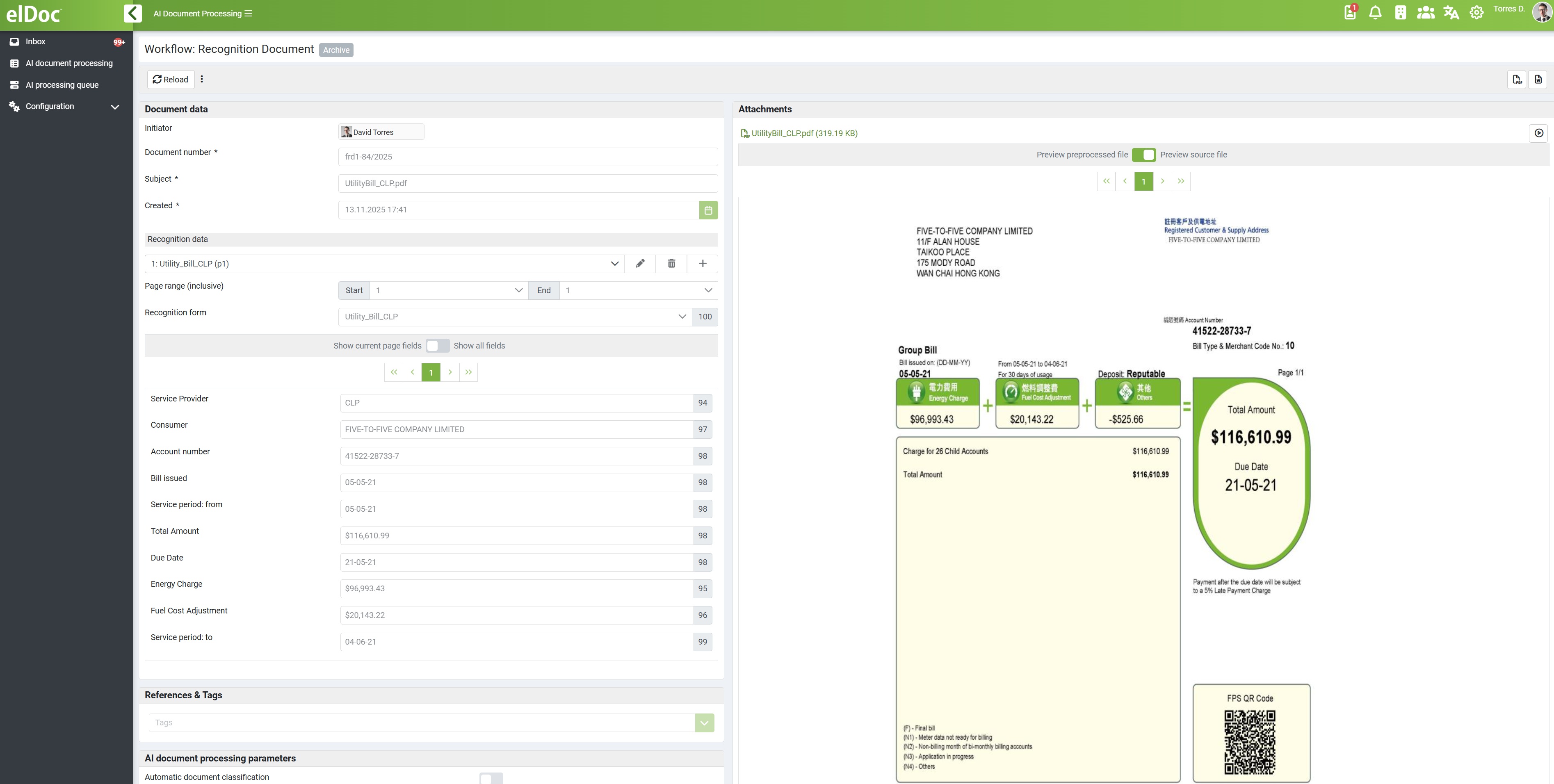
4. Structured Data Output
The interpreted data is immediately converted into structured formats:
✔ JSON for system integrations and APIs
✔ CSV for reporting and data pipelines
✔ Custom schemas aligned with business requirements
This enables instant usability of extracted data without additional transformation layers.
5. Validation & Cross-Checks
To ensure accuracy and compliance, elDoc applies validation mechanisms:
✔ Business rule validation (e.g., totals consistency, mandatory fields, duplicates)
✔ Cross-field validation within the same document
✔ Cross-document validation (e.g., invoice vs. purchase order vs. contract)
✔ Exception detection and anomaly flagging
This ensures that extracted data is not just structured but also reliable and trustworthy.
6. Human-in-the-Loop (Optional)
For sensitive or high-risk workflows, elDoc provides a review interface:
✔ Users can verify, correct, or approve extracted data
✔ Role-based access ensures proper governance and control
✔ Feedback can be used to continuously improve system performance
This step enables a balance between automation and control, especially in regulated environments.
7. Integration
Finally, validated data is seamlessly integrated into downstream systems:
✔ ERP platforms (e.g., SAP, Oracle, NetSuite)
✔ BPM and workflow systems
✔ Data warehouses and analytics platforms
✔ Custom enterprise applications via API
This closes the loop—transforming documents into actionable data that drives business processes.
What elDoc Can Extract
elDoc is designed to handle a wide spectrum of document types across industries, geographies, and use cases regardless of format variability or complexity. By combining AI OCR, Visual Language Models, and LLM-based reasoning, it can extract both structured data and deep contextual information with high accuracy.
Typical document types include:
✔ Invoices → line items, totals, VAT, vendor details, payment terms
✔ Contracts & Agreements → clauses, obligations, key dates, parties, renewal terms
✔ Application Forms → structured fields, personal data, selections, signatures
✔ Bank Statements → account details, transaction history, balances, transaction categorization
✔ Utility Bills → billing periods, consumption data, charges, account identifiers
✔ Company Registry Documents → company names, registration numbers, directors, shareholders, incorporation details
✔ Identity Documents (e.g., HKID) → personal identification data, document numbers, expiry dates (where compliant and permitted)
✔ Transcripts & Certificates → names, grades, subjects, dates, issuing institutions
✔ Financial Documents → balances, ledger entries, summaries, reconciliations
✔ Compliance & Regulatory Documents → required data points, disclosures, reference numbers
Beyond simple field extraction, elDoc can also:
✔ Interpret tabular data and nested structures
✔ Handle multi-page and multi-format documents
✔ Extract data from mixed content (text, tables, stamps, handwritten notes)
✔ Adapt to region-specific document formats and languages
Even highly variable or previously unseen document types can be processed without templates or manual configuration.
Result: elDoc turns virtually any document into structured, validated, and actionable data, ready to power enterprise workflows and decision-making.
Beyond Extraction: From Documents to Decisions
Traditional document processing tools stop at extraction—delivering structured data, but leaving the real work of interpretation, validation, and decision-making to downstream systems or human users.
elDoc goes significantly further.
By integrating Retrieval-Augmented Generation in an agentic framework, elDoc transforms extracted data into an active layer of reasoning, decision-making, and execution.
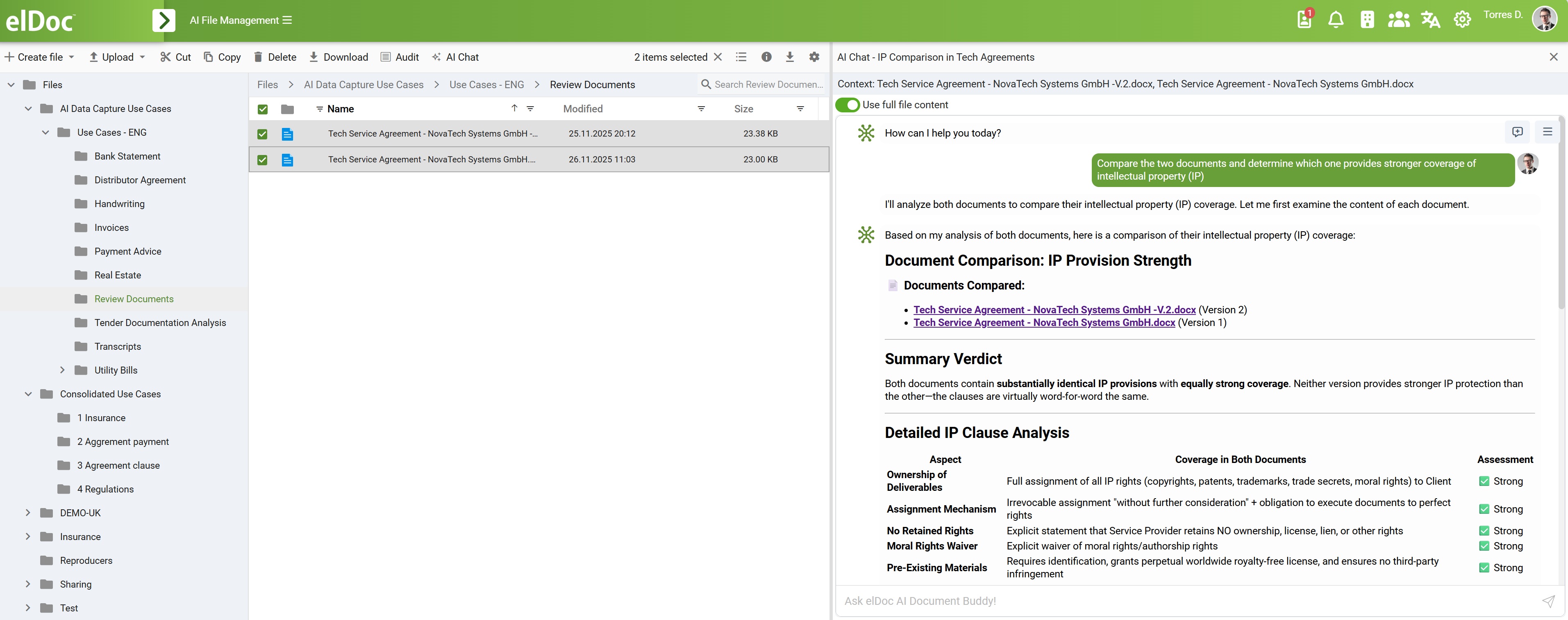
This means documents are no longer just processed - they become operational assets that can be queried, validated, and acted upon in real time.
What Agentic RAG Enables in elDoc
✔ Querying extracted and original document data. Users and systems can interact with both structured outputs and raw documents using natural language—retrieving precise answers without manual search.
✔ Cross-document reasoning. elDoc can compare and correlate information across multiple documents, such as: Invoice vs. Purchase Order vs. Contract, Bank statement vs. reported financials, Application form vs. supporting documentsю
This enables deeper validation and consistency checks that traditional systems cannot perform.
From Technology to Business Impact with DMS Solutions
Transforming document processing requires more than just deploying a platform - it requires the right strategy, architecture, and execution. DMS Solutions ensures that elDoc is not only implemented, but fully aligned with your business objectives and delivers measurable value from day one.
From identifying high-impact use cases such as invoice automation, KYC, compliance, and contract management, to designing secure and scalable architectures (cloud, on-premise, or hybrid), DMS Solutions provides end-to-end guidance tailored to your environment.
Implementation is seamless and business-focused -integrating elDoc with your existing ERP, BPM, CRM, and data systems while configuring intelligent workflows for approvals, validations, and exception handling. This ensures that extracted data flows directly into real operations, not just dashboards.
Beyond deployment, DMS Solutions continuously optimizes performance - improving extraction accuracy, expanding automation across new document types, and ensuring the platform evolves with your business needs. Security, governance, and compliance are embedded throughout, with full support for auditability, access control, and regulatory requirements.