{kind=link}
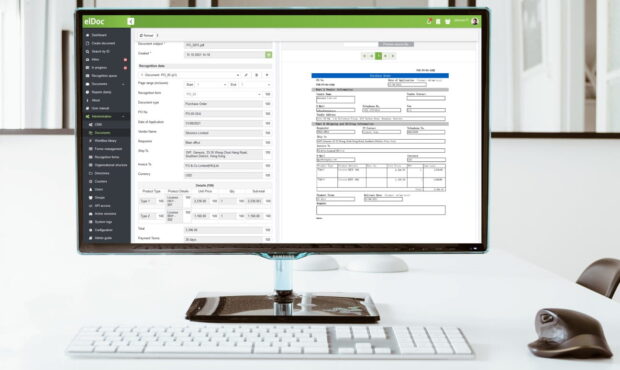
Extract data from PDF or Image (JPEG, PNG, TIFF) in seconds: instant access from anywhere, anytime
Extracting data from various document formats could be a challenging task, especially when it comes to the necessity to extract specific data set from file containing different types of documents that are spanning across multiple pages.
In these quick materials we will list key features that are available in elDoc and which will help you to quickly recognize and extract data from diversified range of documents in seconds.
What are the supported file formats for data extraction?
You may upload to elDoc different type of documents of different formats for data recognition and data extraction:
- Portable Document Format (PDF)
- Joint Photographic Experts Group (JPEG)
- Portable Graphics Format (PNG)
- Tagged Image File Format (TIFF)
What are the supported languages for data recognition?
If you use elDoc on premise – elDoc supports 120+ languages for text recognition. The full list of supported languages could be found here: elDoc Documentation. If you use elDoc in Cloud (SaaS) – elDoc supports 60+ languages for text recognition including but not limited to: Arabic, Armenian, Belorussian, Bulgarian, Catalan, Chinese, Croatian, Czech, Danish, Dutch, English, Estonian, Filipino, Finnish, French, German, Greek, Hebrew, Hindi, Icelandic, Indonesian, Italian, Japanese, Korean, Lao, Latvian, Lithuanian, Macedonian, Nepali, Norwegian, Persian, Polish, Portuguese, Russian, Serbian, Slovak, Slovenian, Spanish, Swedish, Telugu, Thai, Turkish, Ukrainian, Vietnamese, etc.
How to recognize text from PDF or Image (JPEG, PNG, TIFF)?
Herebelow are the key steps for the simple scenario when you need only to recognize the data from your documents (PDF or image) without a need to capture and extract the specific dataset from batch of documents.
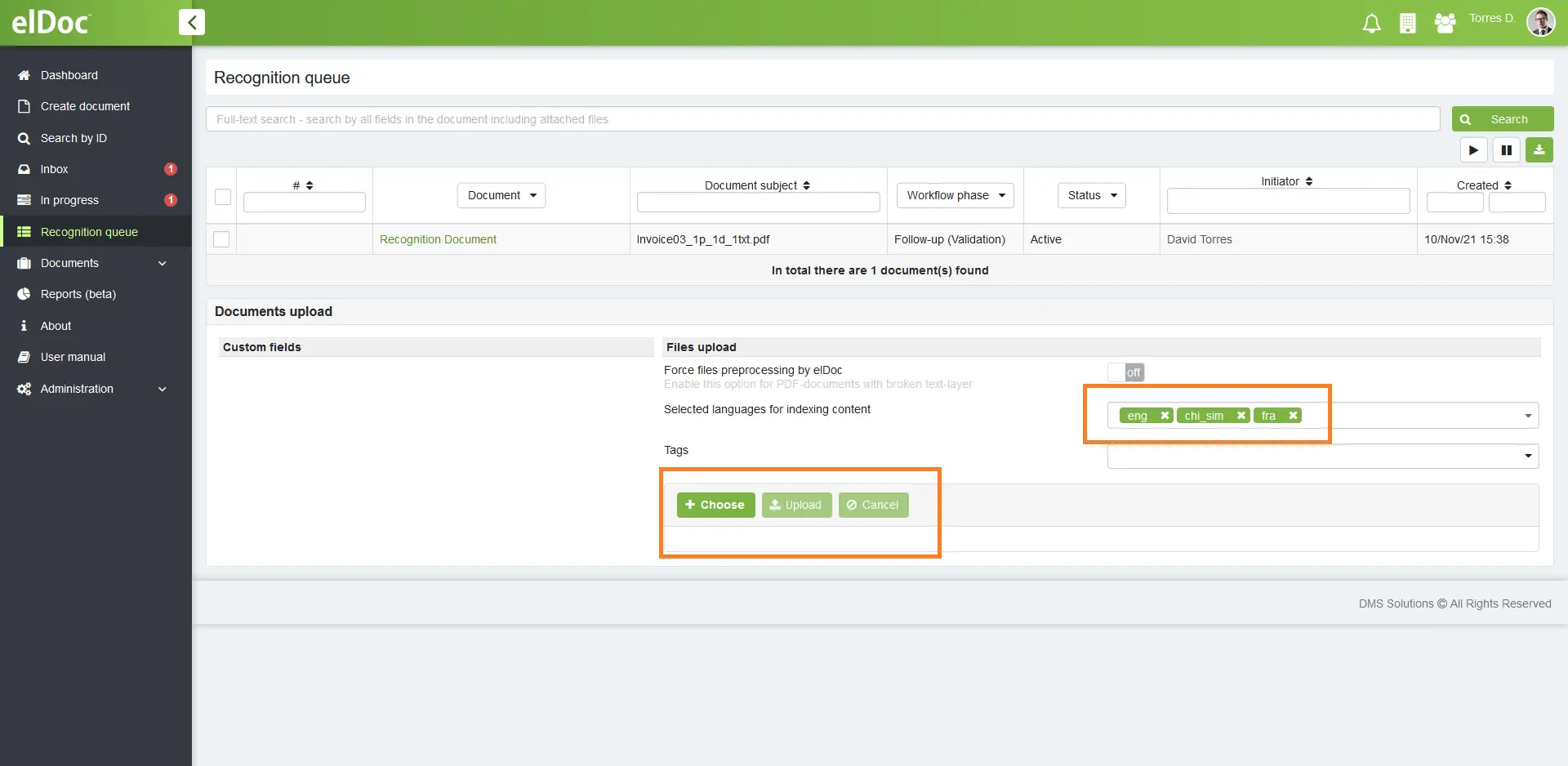
Step 1: Login and Upload your document
It is very simple and straight forward! Login to elDoc ( Get elDoc Trial for Free), navigate to recognition queue and upload the document. You may upload by drag and drop or you may upload batch of documents in one go. You may also specify the language for text recognition where required. elDoc supports 120+ languages for text recognition.
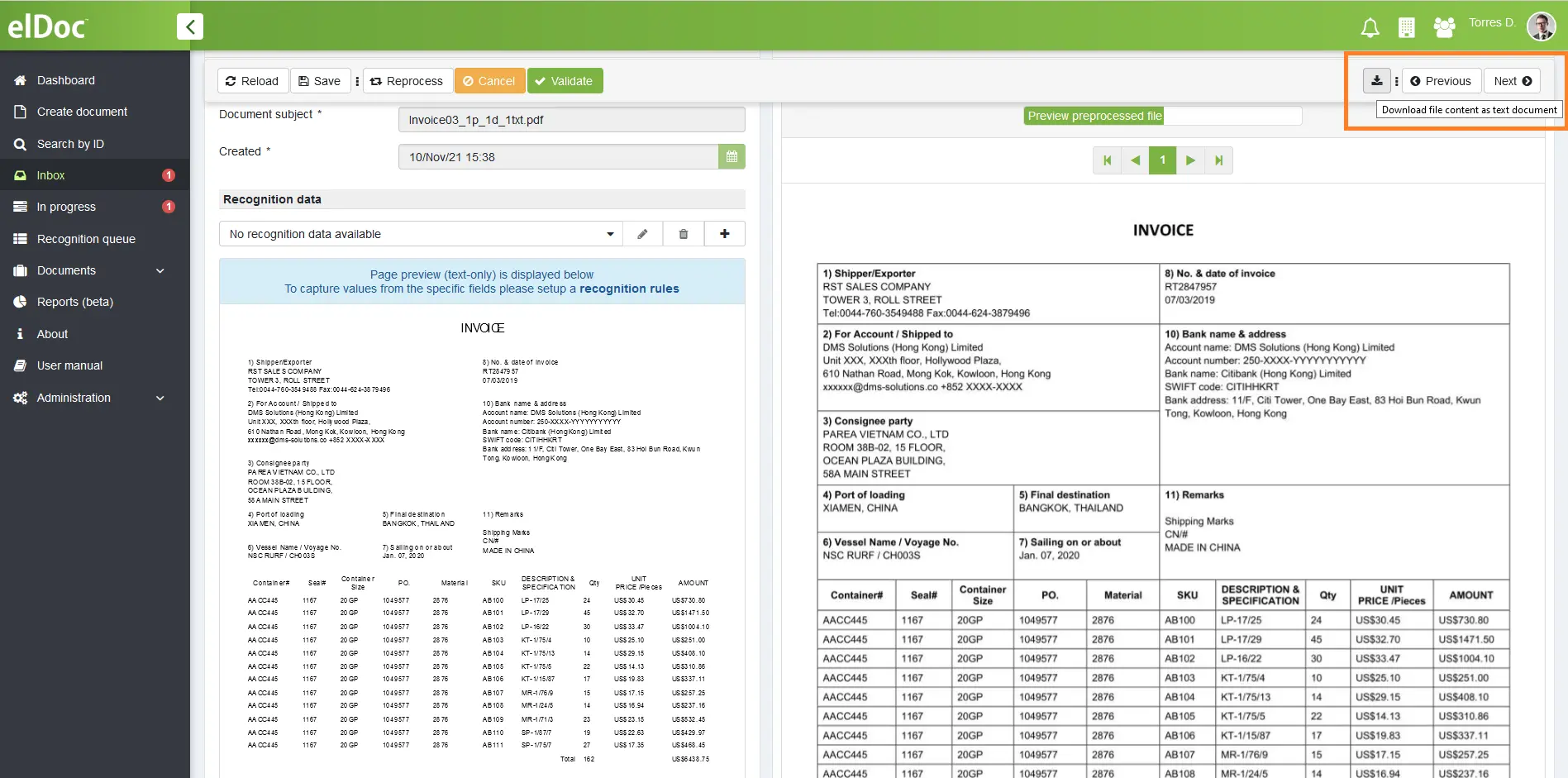
Step 2: Download file content as text document
To convert data to text format - navigate to your Inbox in elDoc, open the recognized document and perform download. And here it goes! Your scanned image is now recognized and is available in text format.
How to extract specific text from PDF or Image (JPEG, PNG, TIFF)?
Herebelow are the key steps for the scenario when you need to recognize and capture the specific data from your documents (PDF or image).
Simply, you just only need to provide the input what fields / data you would like to capture from the specific document type. This might take up to 5-7 minutes of your time and once the setup is performed - elDoc would be capable to classify the documents by type and extract data automatically from the most complex documents. Apply quick on-the-fly setup to process diversified range of documents!
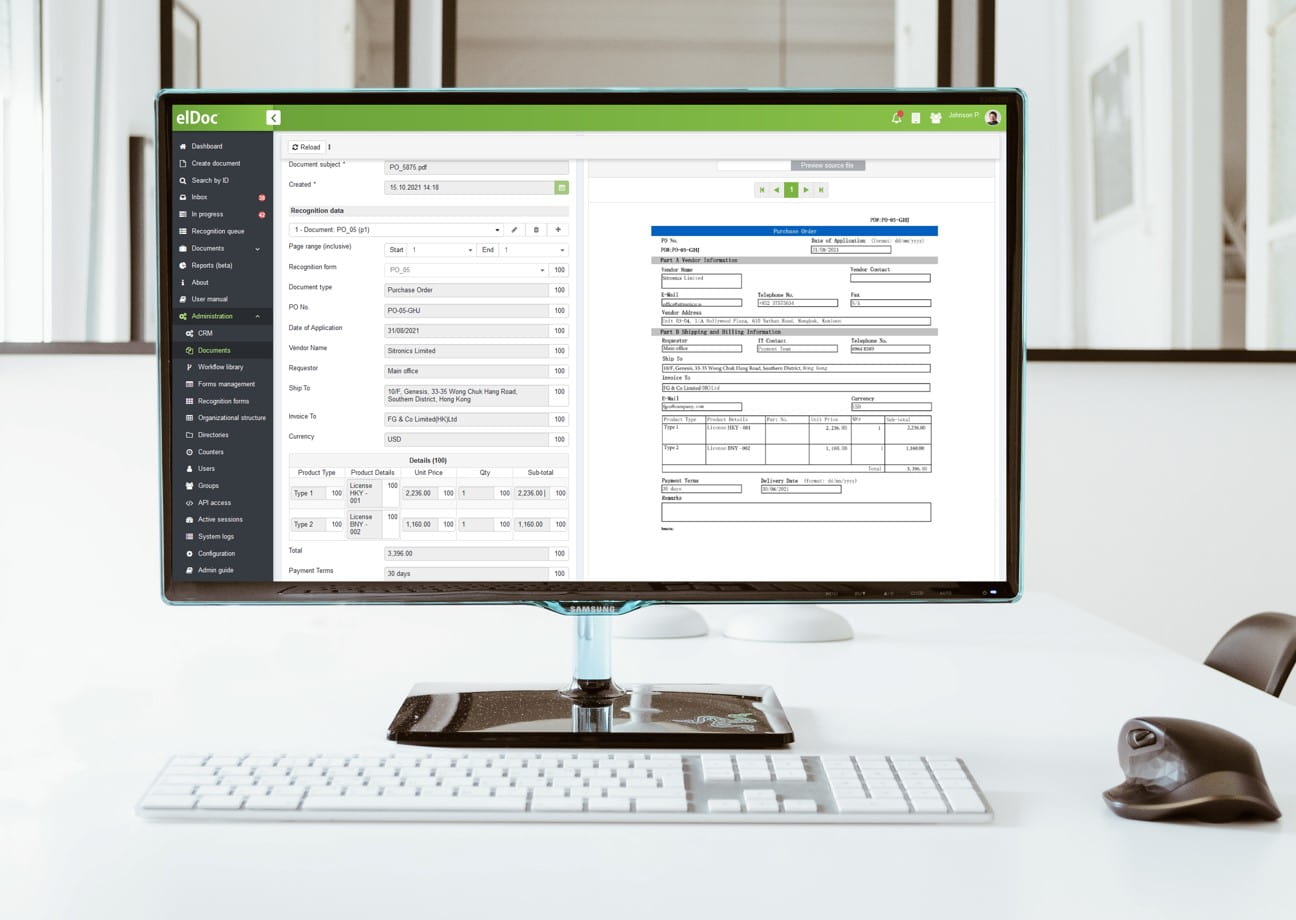
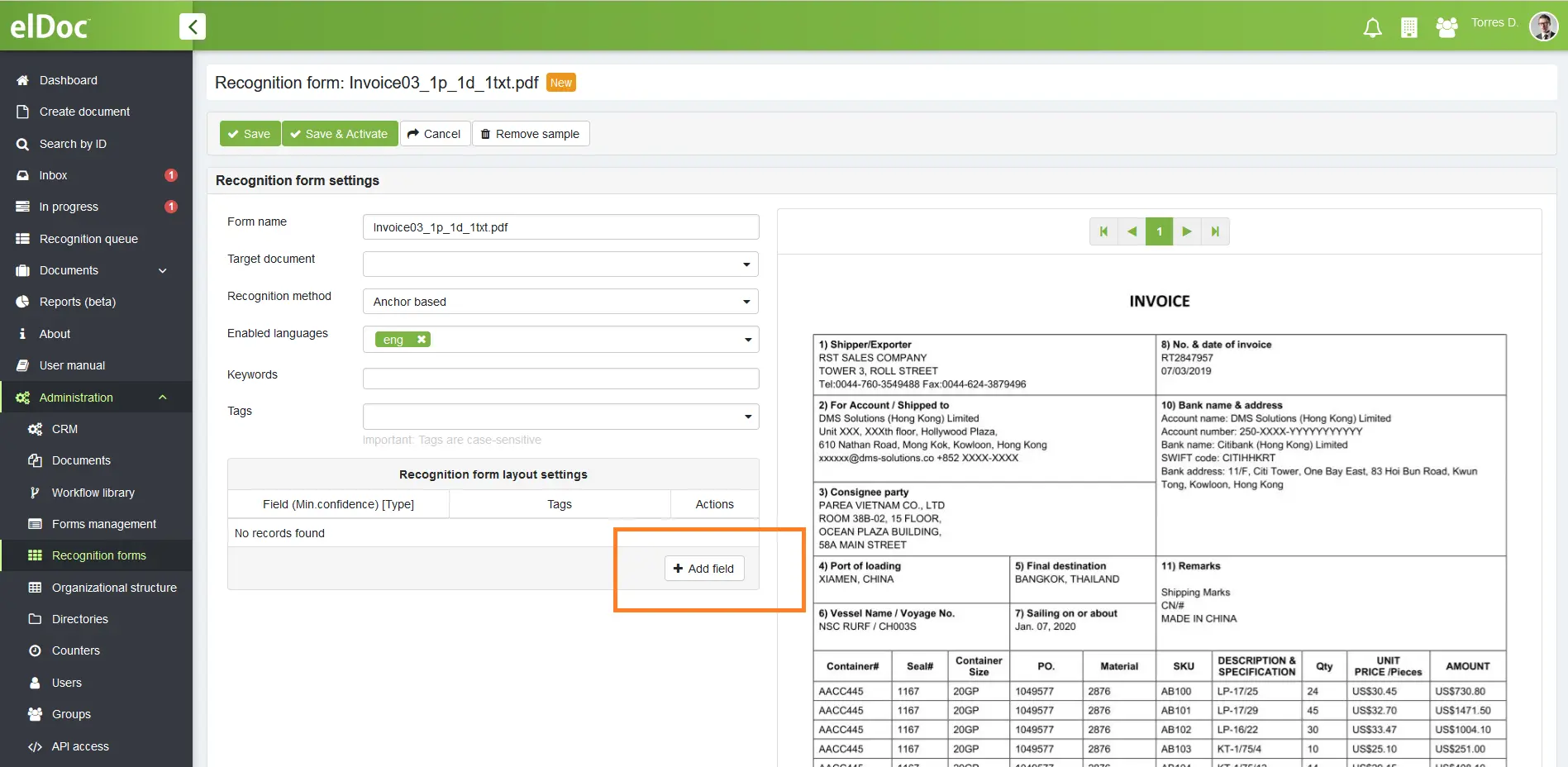
Step 1: Set fields you would like to capture
Navigate to Administration -> Recognition Form -> Create New Form -> Set fields which you would like to capture from your document. Don’t worry if you have multiple-page documents which are dynamically being changed or your table data is dynamically spanning across hundreds of pages – we have got you covered! All these could be easily handled by elDoc – AI powered automation.
Step 2: Upload your document
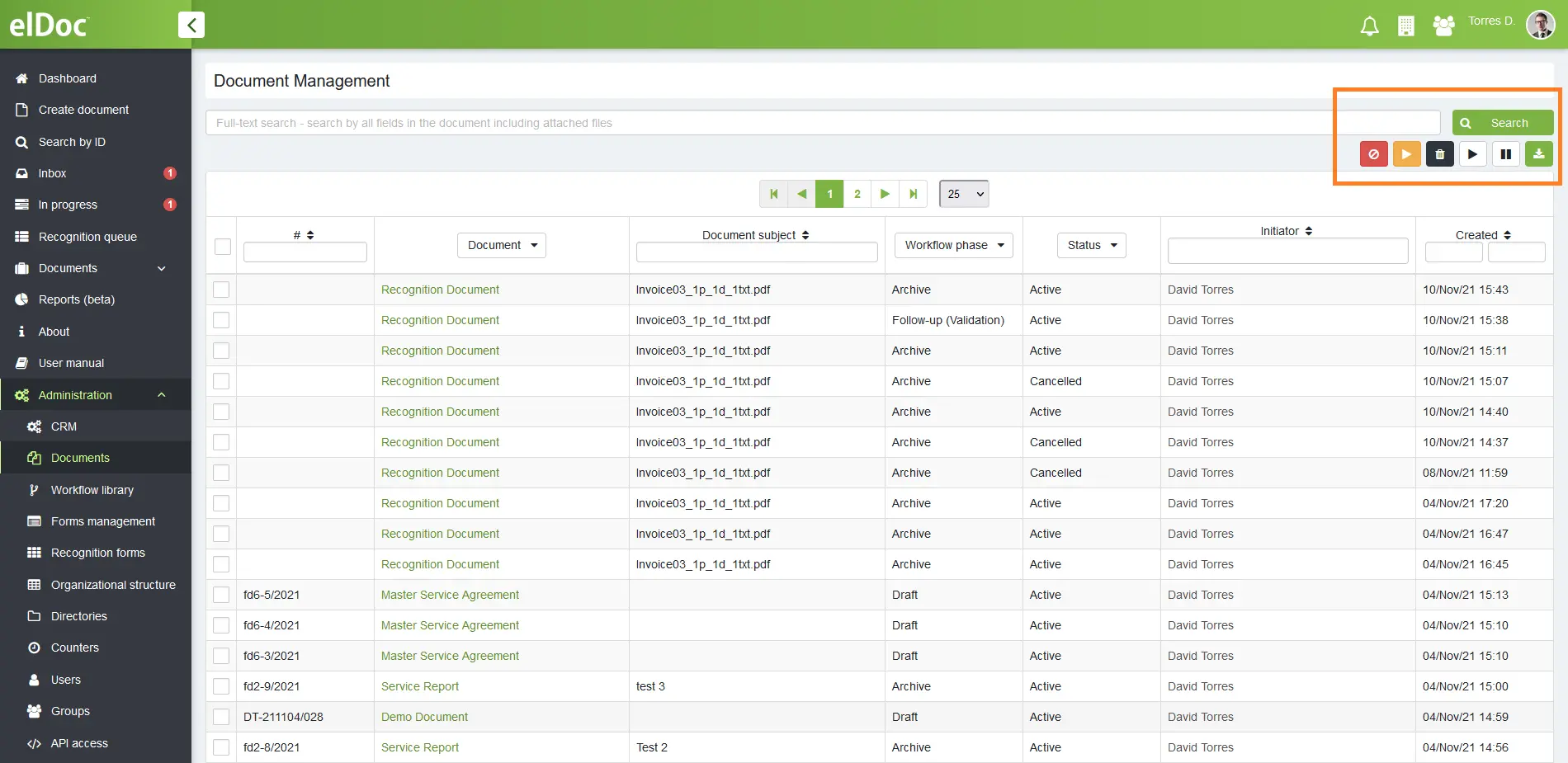
Navigate to recognition queue and upload the documents. By the way, you may also consider automated data entry into third party systems in order to automate document extraction from end-to-end perspective. For more details please see elDoc API documentation.
Step 3: Export recognized data to Excel / CSV or set up automated data entry into other systems
To export the recognized data - navigate to Export control and perform the export. And here it goes! All your data in readable, structured format, ready for further processing. In case you would like to auto feed your recognized, structured data into your target system – you may use elDoc API.
Conclusions:
Leveraging elDoc (either on premise or in Cloud) you may turn any document into structured dataset in seconds. elDoc provides not only with capability to extract and recognize the data, elDoc is a fully featured Integrated Automated Platform for Intelligent Document Processing, No Code Document Workflow Automation and Content Management from Anywhere.
Explore more: automated data extraction from different document types:
Data extraction from Bank Statements
Data extraction from Utility Bills
Data extraction from Invoices
Data extraction from Student Transcripts
Data extraction from Payment Advice
Data extraction from Service Reports

Go beyond OCR with AI
Solve your most critical document processing challenges with "elDoc" - AI-powered Integrated Automated Platform for Intelligent Document Processing, Document Workflow Automation and Content Management.
Choose your deployment option (SaaS or on-prem) that best meets your automation requirements!