{kind=link}
Зчитування та розпізнавання даних з PDF-файлів або зображень у форматах JPEG, PNG, TIFF за лічені секунди
Зчитування та розпізнавання даних з різних форматів документів може виявитись непростим завданням, особливо коли йдеться про необхідність зчитування певного набору даних з багатосторінкового файлу, що містить різні за формою і структурою типи документів.
У цьому короткому огляді ми перерахуємо основні функції, доступні у платформі elDoc, які допоможуть вам швидко розпізнавати та зчитувати дані з найрізноманітніших документів за лічені секунди.
Які формати файлів підтримуються для зчитування даних?
Ви можете завантажувати в elDoc різні типи документів різних форматів для розпізнавання та зчитування даних:
- Portable Document Format (PDF)
- Joint Photographic Experts Group (JPEG)
- Portable Graphics Format (PNG)
- Tagged Image File Format (TIFF)
elDoc також підтримує обробку цифрових документів (електронних документів в форматі PDF). Використовуючи сучасні інноваційні можливості – ви можете завантажувати документи без необхідності іх структурування та виокремлення. Інтелектуальна платформа elDoc підтримує можливість обробки файлів, що містять різноманітні форми документів PDF, PNG, JPEG, TIFF.
Які мови підтримуються для розпізнавання даних?
При локальному варіанті розгортання elDoc підтримує понад 120 мов для розпізнавання тексту. Повний список підтримуваних мов можна знайти за посиланням: підтримка мов в elDoc. При використанні інтегрованої автоматизованої платформи у хмарі (за моделлю SaaS) elDoc підтримує понад 60 мов для розпізнавання тексту, зокрема: англійську, арабську, білоруську, болгарську, в’єтнамську, вірменську, гінді, грецьку, данську, естонську, іврит, індонезійську, ісландську, іспанську, італійську, каталонську, китайську, корейську, лаоську, латвійську, литовську, македонську, непальську, нідерландську, німецьку, норвезьку, перську, польську, португальську, російську, сербську, словацьку, словенську, тайську, телуґу, турецьку, українську, філіппінську, фінську, французьку, хорватську, чеську, шведську, японську тощо.
Важливим функціоналом elDoc також є можливість розпізнавання та зчитування декількох мов з одного документа.
Як здійснюється розпізнавання тексту з PDF-файлів або зображень у форматах JPEG, PNG, TIFF?
Нижче наведено основні кроки для сценарію, коли вам потрібно лише розпізнати дані з ваших PDF-документів або зображень у форматах JPEG, PNG, TIFF без необхідності визначення та зчитування конкретного набору даних та полів з пакету документів.
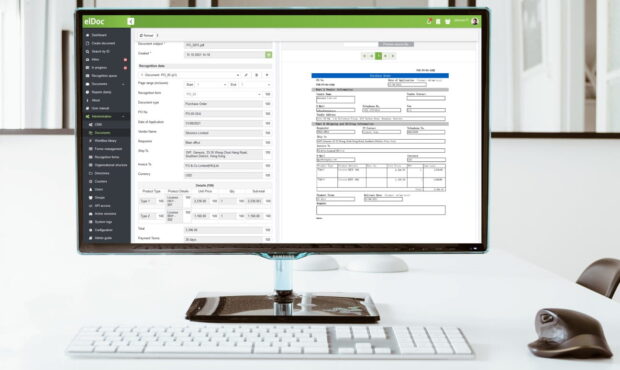
Крок 1: Увійдіть у систему й завантажте свій документ
Тут все просто і зрозуміло. Увійдіть у систему elDoc ( отримати безкоштовну пробну версію elDoc ), перейдіть до меню черги розпізнавання та завантажте документ. Ви можете завантажити документ за допомогою функціоналу Drag & Drop або завантажити цілий пакет документів за один раз. За необхідності ви також можете вказати мову для розпізнавання тексту. Функціонал внесення конфігураційних налаштувань з вибору мову доступний у версії elDoc для локального розгортання. У хмарі (за моделлю SaaS) – вибір мови здійснюється автоматично. elDoc підтримує понад 120 мов для розпізнавання тексту.
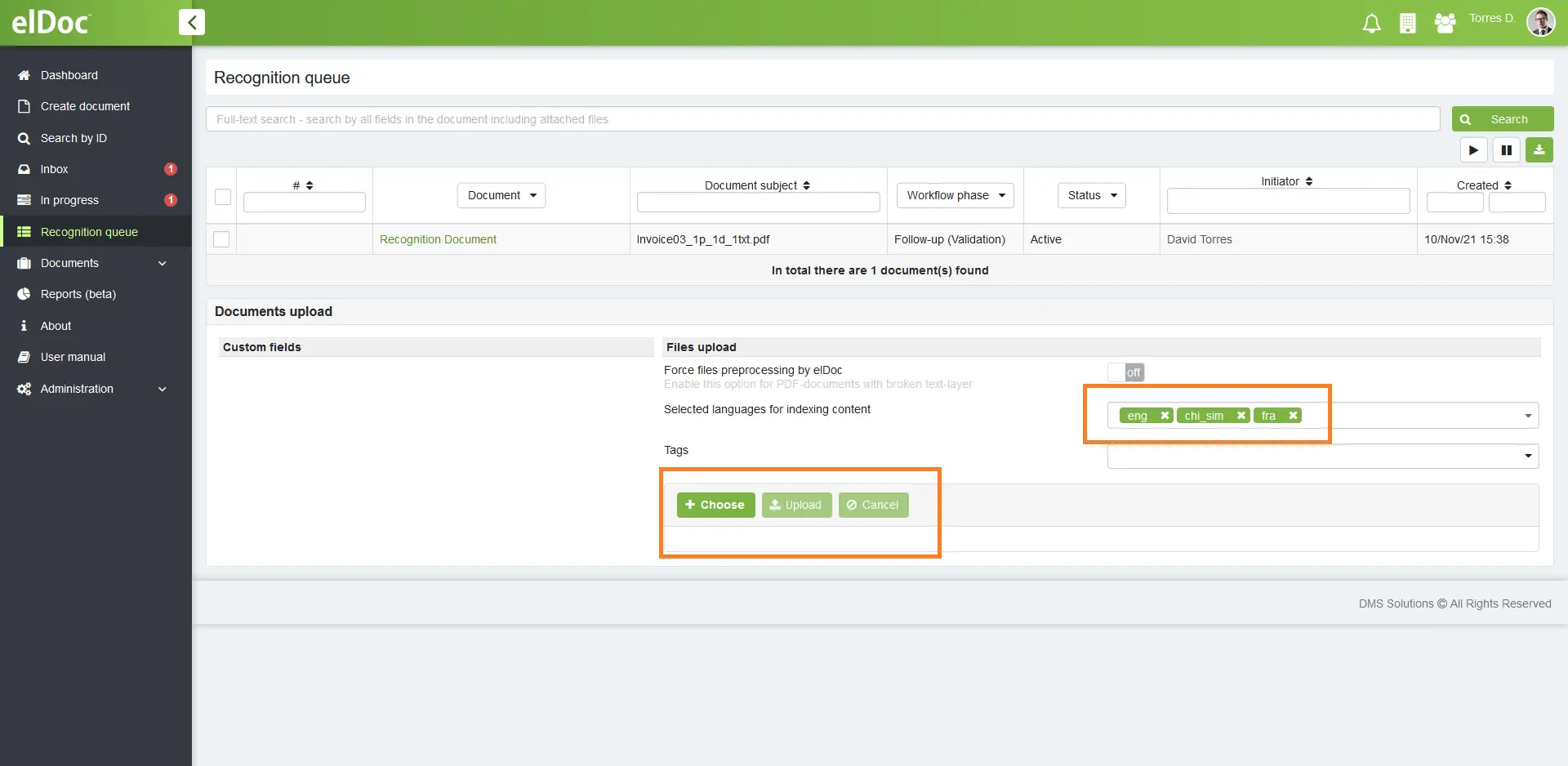
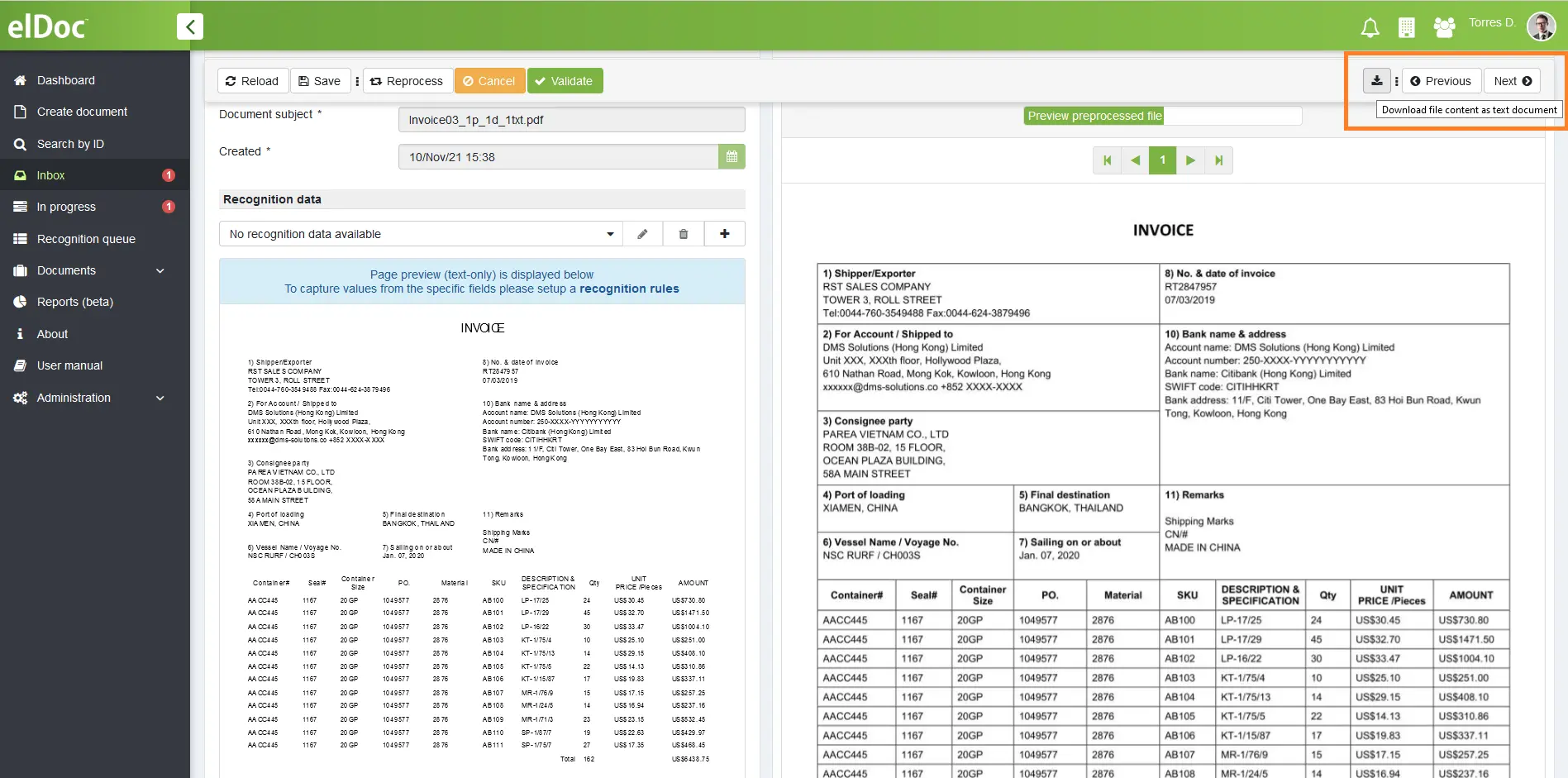
Крок 2: Як вивантажити вміст сканованого файлу у текстовий формат?
Щоб конвертувати дані в текстовий формат, перейдіть до меню «Вхідні» в elDoc, відкрийте розпізнаний документ і виконайте вивантеження. Після вивантеження - зображення буде доступне в текстовому форматі.
Як зчитати цільові дані з PDF-файлів або зображень у форматах JPEG, PNG, TIFF?
Нижче наведено ключові кроки для сценарію, коли вам потрібно розпізнати та зчитати конкретні дані з ваших PDF-документів або зображень у форматах JPEG, PNG, TIFF.
Для цього вам потрібно лише вказати, які поля / дані вам необхідно отримати з певного типу документа. Здійснення такого налаштування може зайняти до 5-7 хвилин вашого часу, і як тільки налаштування буде виконано, elDoc зможе класифікувати документи за типом і автоматично зчитувати дані з найскладніших за формою документів. Застосовуйте швидке налаштування «на льоту» для обробки найрізноманітніших документів!
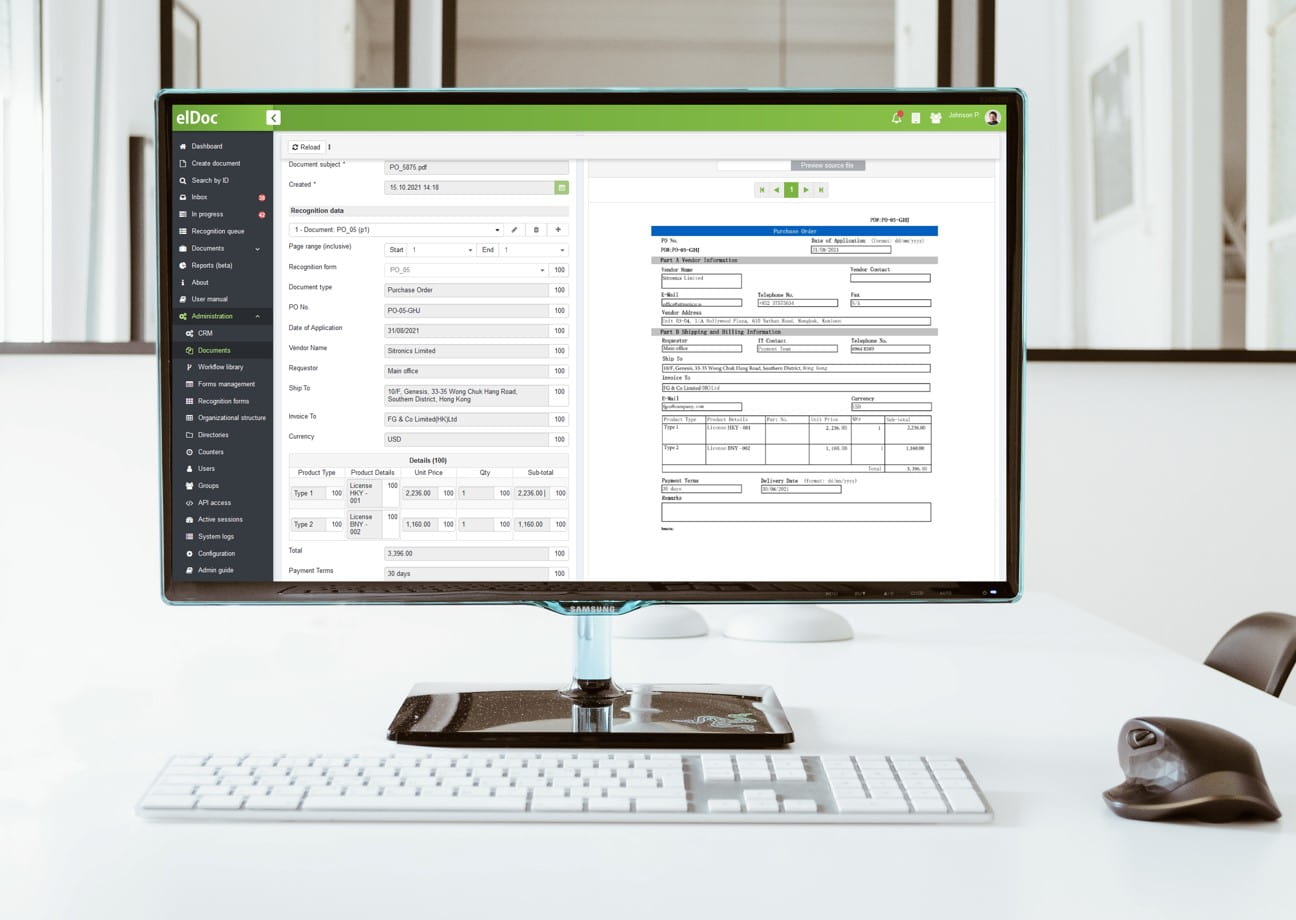
Крок 1: Встановіть поля, які вам необхідно зчитати
Перейдіть до розділу Адміністрування -> Форма розпізнавання -> Створити нову форму -> Встановити поля, які вам необхідно зчитати зі свого документа. Якщо маєте справу з багатосторінковими документами або табличними за формою документами, які динамічно охоплюють сотні сторінок - з усім цим легко можна впоратися за допомогою elDoc – автоматизованої платформи на основі штучного інтелекту.
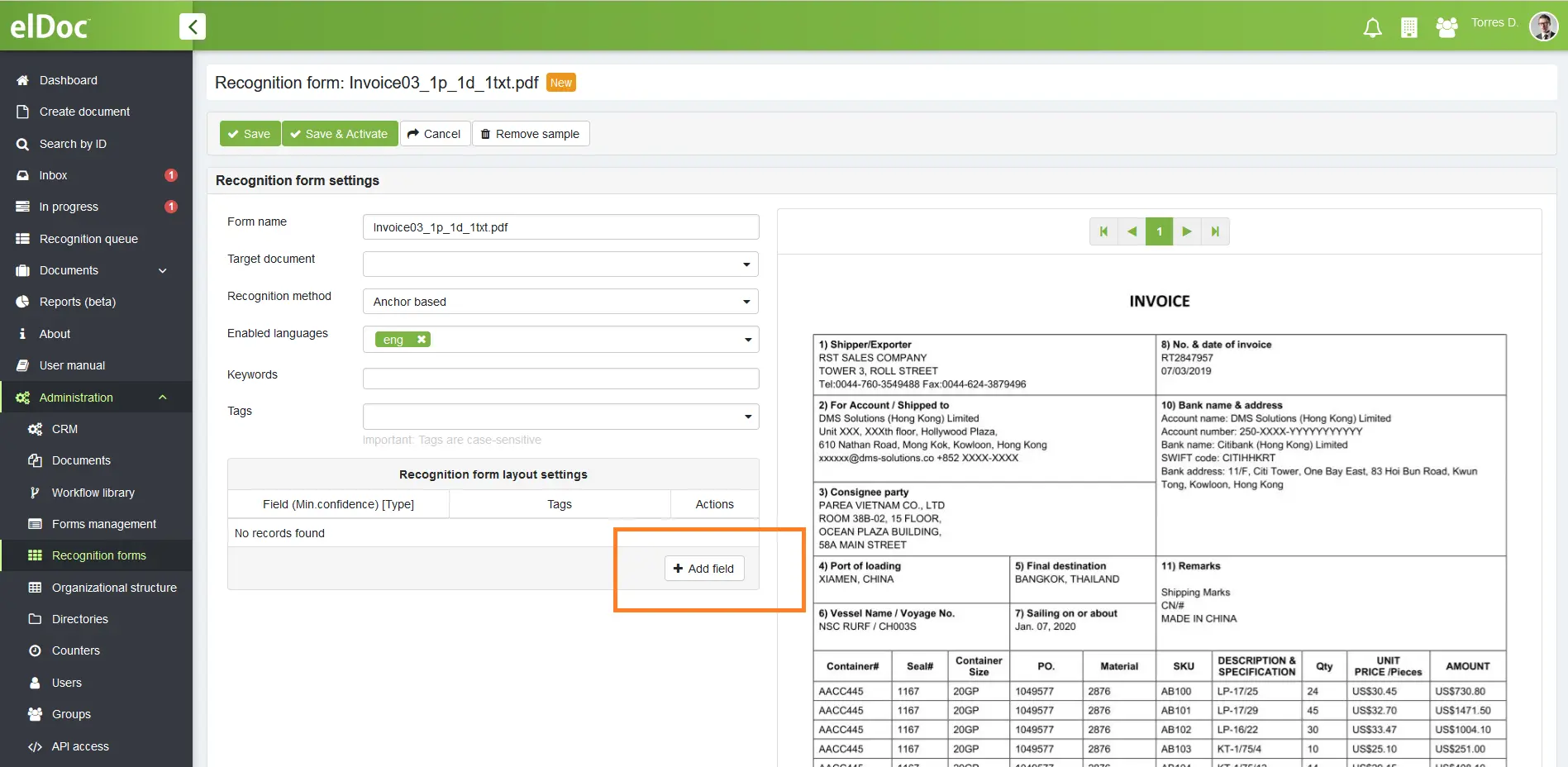
Крок 2: Завантажте ваш документ
Перейдіть до черги розпізнавання та завантажте документи. До речі, з elDoc також можливе автоматизоване введення даних у сторонні додатки з метою комплексної автоматизації зчитування даних з документів. Більше додаткової інформації щодо побудови інтеграції з іншими системами ви можете знайти в документації elDoc API.
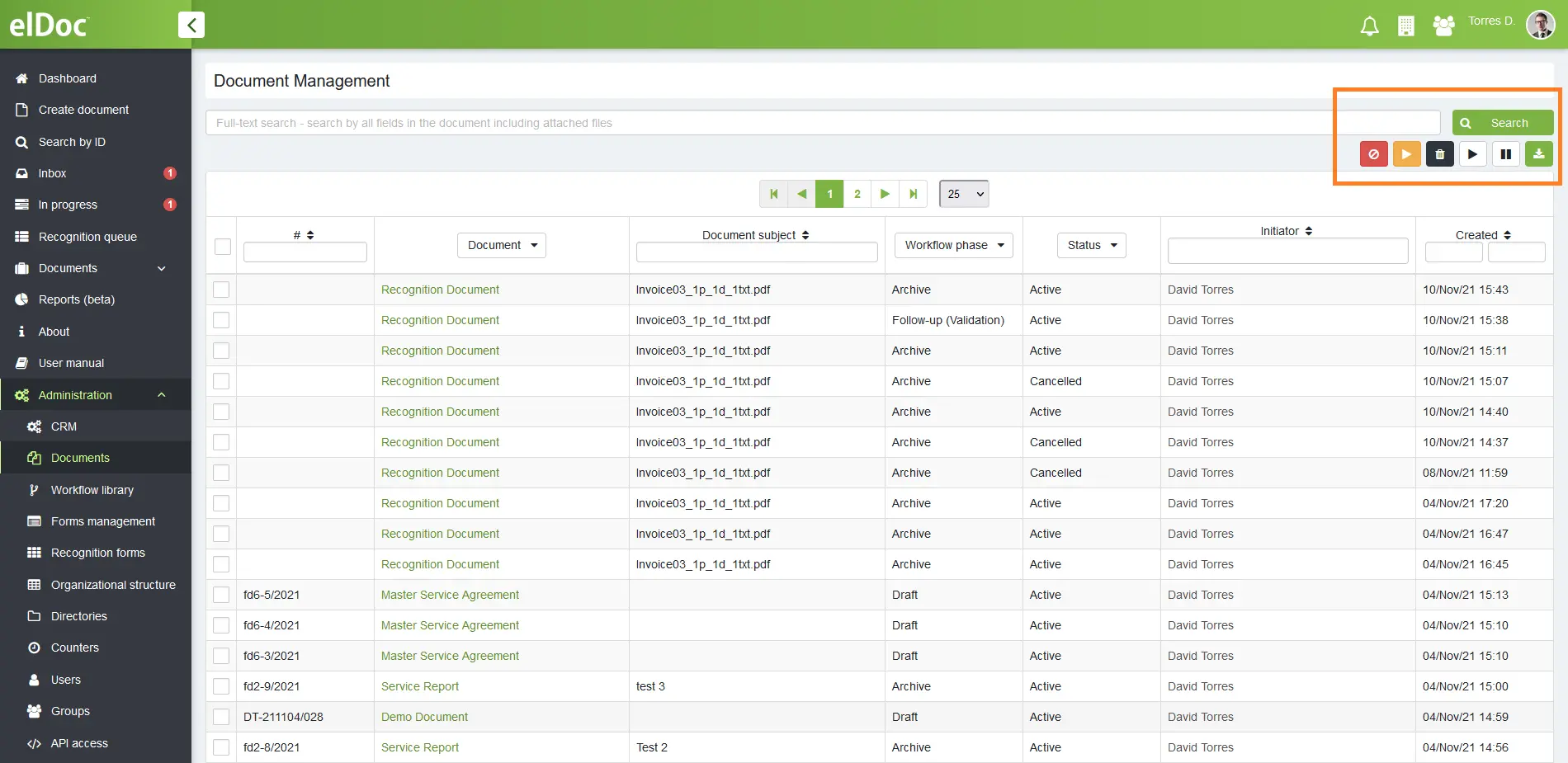
Крок 3: Експортуйте розпізнані дані в Excel / CSV формат або налаштуйте автоматичне введення даних в інші системи
Щоб експортувати розпізнані дані, перейдіть у розділ контроль експорту та виконайте експорт. Після експорту - всі ваші дані в структурованому форматі – готові до подальшої обробки. Якщо ви плануєте автоматично передати розпізнані структуровані дані у вашу цільову систему, ви можете скористатися можливістью elDoc API.
Підсумки:
Використовуючи elDoc (як локально, так і в хмарі), ви можете розпізнавати та зчитувати дані з будь-якого документу з подальшим перетворенням даних у структурований формат за лічені секунди. elDoc надає можливості не тільки зчитувати та розпізнавати потрібні вам дані. elDoc — це повнофункціональна інтегрована автоматизована платформа для інтелектуальної обробки документів, No Code автоматизації документообігу та управління контентом з будь-якого робочого місця.
Більше інформації про автоматизоване зчитування даних з різних типів документів можна отримати за наступними посиланнями:
Зчитування даних з банківських виписок
Зчитування даних з рахунків на оплату
Зчитування даних з аплікаційних документів
Бажаєте перевірити, як інтелектуальне зчитування даних з документів працює на практиці? – отримайте безкоштовну пробну версію elDoc!
Про «elDoc»
«elDoc» – інтегрована інтелектуальна автоматизована платформа для розуміння документів, автоматизації процесів документообігу та управління контентом з будь-якого робочого місця. «elDoc» – це рішення корпоративного рівня, доступне як SaaS та on-prem, для комплексної інтелектуальної обробки документів (Intelligent Document Processing) та управління бізнес-процесами (Business Process Management). elDoc оснащений когнітивними технологіями (штучним інтелектом, комп’ютерним баченням), які допомагають інтелектуально зчитувати дані зі сканованих та цифрових документів будь-якої складності з подальшою їх комплексною обробкою.
Про «DMS Solutions»
Компанія «DMS Solutions» – розробник інтегрованої інтелектуальної автоматизованої платформи для розуміння документів, автоматизації процесів документообігу та управління контентом з будь-якого робочого місця – «elDoc».
Ми – перший український провайдер рішень у сфері інтелектуальної обробки документів (Intelligent Document Processing). Ми використовуємо технології комп’ютерного бачення, машинного навчання та штучного інтелекту з метою створення потужної цифрової робочої сили для забезпечення конкурентних переваг вашого бізнесу на ринку. «DMS Solutions» є офіційним глобальним Advanced Technology UiPath Alliance Partner та Technology Blue Prism Alliance Partner у сфері інтелектуальної обробки документів (Intelligent OCR).